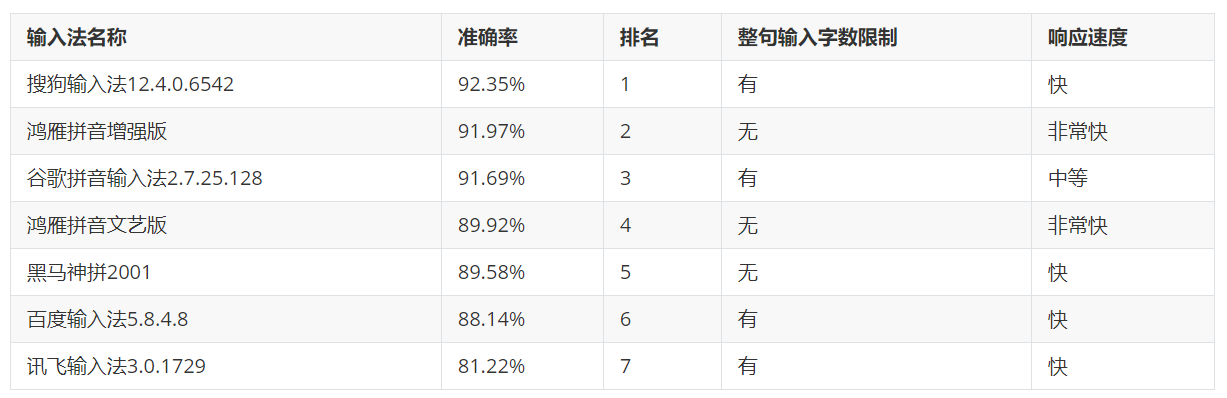
为什么搜狗输入法这么一枝独秀?那是因为王小川曾经获得国际奥林匹克信息学竞赛金牌。
为什么黑马神拼这个20多年前的输入法还是老当益壮?那是因为其开发者王励在联想汉卡待了三年多,在中文处理上积累了丰富经验。
为什么名不经传的鸿雁拼音输入法能够取得第二名的好成绩?那是因为开发者鸿雁想验证自己一个猜想,大规模高质量语料的词频统计或许可以达到阿尔法狗左右互搏的效果。从零开始,不学习任何中文语法、分词的经验,仅仅依靠概率统计,同样也可以获得中文语言的规律。
鸿雁拼音输入法下载链接:
https://hong-yan.lanzouw.com/b00vvkivc 密码:1234
鸿雁输入法是一个开源免费的软件。源代码可以审查,不会搜集客户的隐私。
鸿雁输入法没有弹窗广告,没有强制升级。
鸿雁输入法的词频统计来自350GB的典型语料库,原始统计的词语有5.14亿个
鸿雁输入法并未采用中文语法算法引擎,仅仅依靠统计学的数据做成的候选词排名
鸿雁拼音采用的高权词库包括:
百度百科中文标题(约380万条) 开源分词数据(220万) A+医学百科医学名词(20万) 中文常见人名(120万) 中华人民共和国行政区划(五级):省级、地级、县级、乡级和村级(76万) 现代汉语词典(5.5万) 百度百科与维基百科的词条标题的交集(约50万条) 唐诗三百首、宋词三百首、老子道德经、论语、诗经的整句 李白诗句全集 世界各个国家国名全称、简称
鸿雁拼音词频统计使用的语料库包括:
epubee整站电子书5.3万本 全网能找到的所有微博语料 百度百科2400多万条 各类博客4000多万条 中文维基百科全部条目 各类新闻语料 微信公众号语料 联合国平行语料库中文部分 1946年-2003年人民日报全部数据纯文本


